Neural Networks with Candle
📚 Attribution: The examples and explanations here are based on Appendix A (the PyTorch introduction) from Build a Large Language Model (From Scratch) by Sebastian Raschka, with the Python/PyTorch code ported to Rust/Candle. The diagrams are also adapted from the book.
This is a small guide for getting started with neural networks in Rust using Candle — a minimalist ML framework by Hugging Face. If you want to get hands-on with ML in Rust, this guide takes you from basic tensor operations to building and training a complete neural network.
Why Candle?
Candle is designed to be simple and easy to use. If you've used PyTorch before, many concepts will feel familiar:
- Tensors as the core data structure
- Similar operations for creating and manipulating tensors
- Automatic differentiation for gradients
- GPU support when you need it
- Pure Rust, no Python runtime needed
Another advantage is that Candle's API is intentionally similar to PyTorch, which makes porting code pretty straightforward.
Setting Up Candle
To get started with Candle, add it to your Cargo.toml file:
[]
= "0.9.1"
= "0.9.1"
= "0.9.2"
candle-core: Contains tensors and basic operationscandle-nn: Provides neural network layers, optimizers, and loss functionsrand: Used for shuffling data in the DataLoader
CPU vs GPU
By default, Candle works on CPU. If you want GPU support, you can enable CUDA features:
[]
= { = "0.9.1", = ["cuda"] }
= { = "0.9.1", = ["cuda"] }
You'll need CUDA installed on your system for GPU support. All examples in this post use CPU, so that you can follow along on any machine.
Note: This guide uses Candle version 0.9.1. As Candle is actively developed, some APIs may change in future versions. Check the official documentation for the latest updates.
Understanding Tensors
Tensors represent a mathematical concept that generalizes vectors and matrices to potentially higher dimensions. In other words, tensors are mathematical objects that can be characterized by their order (or rank), which provides the number of dimensions.
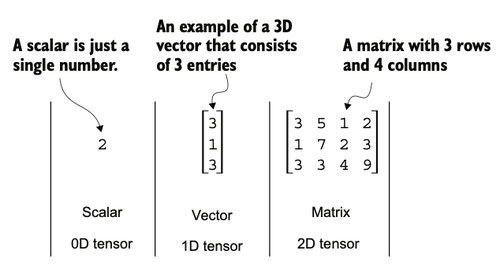
For example, a scalar (just a number) is a tensor of rank 0, a vector is a tensor of rank 1, and a matrix is a tensor of rank 2. A three-dimensional vector, which consists of three elements, is still a rank 1 tensor.
Tensors as Data Containers
From a computational perspective, tensors serve as data containers. They hold multidimensional data, where each dimension represents a different feature. Tensor libraries like Candle can create, manipulate, and compute with these arrays efficiently. In this context, a tensor library functions as an array library.
Candle tensors are similar to PyTorch tensors but built for Rust. They have several features that are important for deep learning:
- An automatic differentiation engine for computing gradients
- GPU support to speed up deep neural network training
- Efficient operations optimized for machine learning
Candle adopts a PyTorch-like API for its tensor operations, which makes it familiar if you've used PyTorch before.
Creating Tensors
As mentioned earlier, Candle tensors are data containers for array-like structures. A scalar is a zero-dimensional tensor (just a number), a vector is a one-dimensional tensor, and a matrix is a two-dimensional tensor. For higher dimensions, we refer to them as 3D tensors, 4D tensors, and so on.
We can create Candle tensors using the Tensor::new function:
use ;
In Candle, we need to specify a device (CPU or GPU) when creating tensors. The ? operator handles potential errors that might occur during tensor creation.
Tensor Data Types
When creating tensors in Candle, the data type depends on what values you provide. We can check a tensor's data type using the .dtype() method:
let tensor1d = new?;
println!;
This prints:
U8
If we create tensors from floating-point numbers, Candle uses the type from Rust's default float literal, which is 64-bit:
let floatvec = new?;
println!;
The output is:
F64
However, for deep learning, 32-bit floating-point precision is usually preferred. It offers sufficient precision for most tasks while consuming less memory and computational resources than 64-bit. GPU architectures are also optimized for 32-bit computations, which speeds up model training and inference.
Changing Data Types
You can change the precision using a tensor's to_dtype method. The following code demonstrates changing a tensor to 32-bit or 8-bit:
let tensor = new?;
println!; // F64
let tensor = tensor.to_dtype?;
println!; // F32
let tensor = tensor.to_dtype?;
println!; // U8
Candle supports various data types including F64, F32, U8, U32, and more. You can find them in the candle_core::DType enum.
Common Tensor Operations
Comprehensive coverage of all the different Candle tensor operations is not included in this post. However, we will cover the most relevant operations you'll need for building neural networks.
We've already seen how to create tensors using Tensor::new:
let tensor2d = new?;
println!;
This prints:
[[1., 2., 3.],
[4., 5., 6.]]
Tensor[[2, 3], f64]
Checking Tensor Shape
The .shape() method allows us to access the shape of a tensor:
println!;
The output is:
[2, 3]
This means the tensor has two rows and three columns.
Reshaping Tensors
To reshape the tensor into a 3 × 2 tensor, we can use the .reshape method:
println!;
This prints:
[[1., 2.],
[3., 4.],
[5., 6.]]
Tensor[[3, 2], f64]
Note that Candle's reshape requires the new shape to have the same total number of elements as the original tensor.
Transposing Tensors
We can use .t() to transpose a tensor, which means flipping it across its diagonal:
println!;
The output is:
[[1., 4.],
[2., 5.],
[3., 6.]]
Tensor[[3, 2], f64]
Matrix Multiplication
The common way to multiply two matrices in Candle is the .matmul method:
println!;
The output is:
[[14., 32.],
[32., 77.]]
Tensor[[2, 2], f64]
Note that in Candle, we need to use a reference (&) when passing tensors to methods like matmul to avoid moving the tensor.
These are the basic operations you'll use most often. Additional operations will be introduced as needed throughout this post.
Seeing Models as Computation Graphs
Now let's look at Candle's automatic differentiation engine. Candle's autograd system provides functions to compute gradients in computational graphs automatically.
A computational graph is a directed graph that allows us to express and visualize mathematical expressions. In the context of deep learning, a computation graph lays out the sequence of calculations needed to compute the output of a neural network—we need this to compute the required gradients for backpropagation, the main training algorithm for neural networks.
A Concrete Example
Let's look at a concrete example to illustrate the concept of a computation graph. The following code implements the forward pass (prediction step) of a simple logistic regression classifier, which can be seen as a single-layer neural network. It returns a score between 0 and 1, which is compared to the true class label (0 or 1) when computing the loss.
use ;
use sigmoid;
use binary_cross_entropy_with_logit;
If not all components in the preceding code make sense to you, don't worry. The point of this example is not to implement a logistic regression classifier but rather to illustrate how we can think of a sequence of computations as a computation graph.
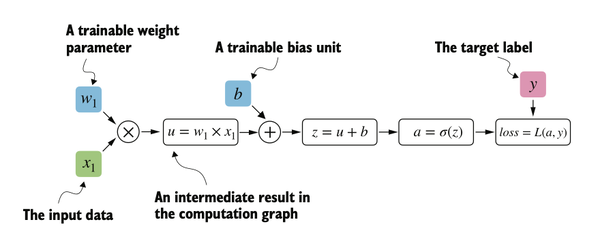
The computation flows like this:
- Input feature
x1is multiplied by weightw1 - Bias
bis added to get net inputz - Sigmoid activation function produces output
a - Loss is computed by comparing output
awith target labely
Candle builds such a computation graph in the background, and we can use this to calculate gradients of a loss function with respect to the model parameters (here w1 and b) to train the model.
Note: In the code, we pass z (not a) to binary_cross_entropy_with_logit because this function combines the sigmoid activation and binary cross-entropy loss computation for numerical efficiency. The variable a is computed separately to illustrate the full computation graph as shown in the diagram.
Automatic Differentiation Made Easy
If we carry out computations in Candle, we can build a computational graph to compute gradients. Gradients are required when training neural networks via the popular backpropagation algorithm, which can be considered an implementation of the chain rule from calculus for neural networks.
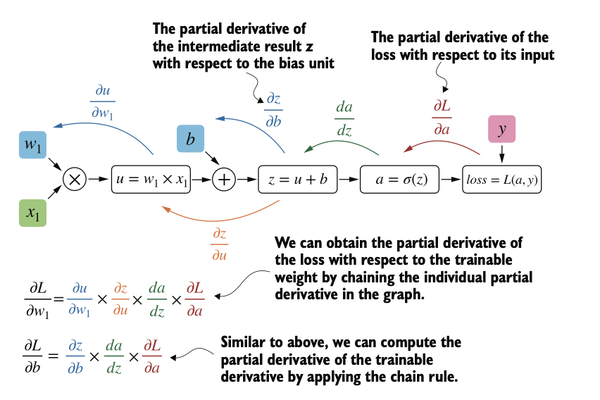
Partial Derivatives and Gradients
Partial derivatives measure the rate at which a function changes with respect to one of its variables. A gradient is a vector containing all of the partial derivatives of a multivariate function—a function with more than one variable as input.
If you're not familiar with partial derivatives, gradients, or the chain rule from calculus, don't worry. On a high level, all you need to know is that the chain rule is a way to compute gradients of a loss function given the model's parameters in a computation graph. This provides the information needed to update each parameter to minimize the loss function, which serves as a proxy for measuring the model's performance.
Computing Gradients in Candle
How is this related to automatic differentiation? Candle's autograd (automatic differentiation) engine constructs a computational graph by tracking operations performed on Var tensors (variables). Then, by calling .backward(), we can compute the gradients of the loss with respect to the model parameters.
In Candle, we mark tensors that need gradient tracking using the Var type:
use ;
use binary_cross_entropy_with_logit;
This prints:
[-0.0898]
Tensor[[1], f64]
[-0.0817]
Tensor[[1], f64]
The key differences from regular tensors:
- We create
Varinstead ofTensorfor parameters that need gradients - We use
w1.as_tensor()to get the underlying tensor for computations - We call
loss.backward()to compute all gradients - We retrieve gradients using
grads.get(&variable)
While the calculus concepts may seem overwhelming, all you need to know is that Candle takes care of the calculus for us via the .backward() method—we won't need to compute any derivatives or gradients by hand. Candle automatically tracks operations and computes the necessary gradients for training neural networks.
Implementing Multilayer Neural Networks
Next, we focus on Candle as a library for implementing deep neural networks. To provide a concrete example, let's look at a multilayer perceptron—a fully connected neural network as illustrated below.
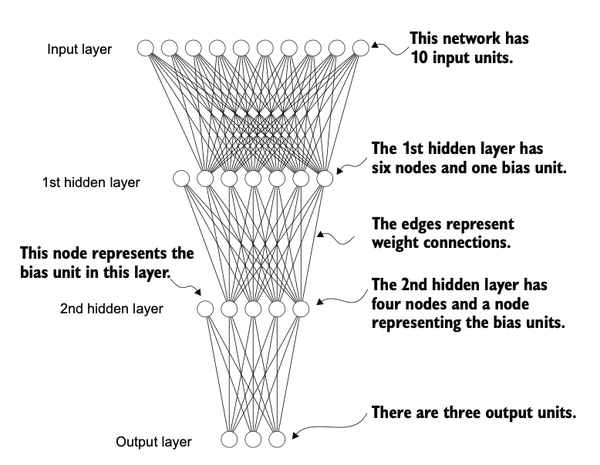
Defining a Neural Network
When implementing a neural network in Candle, we can define a struct to hold our layers and implement the Module trait to specify the forward pass. This approach provides structure and makes it easier to build and train models.
Within our struct, we define the network layers in the new function and specify how the layers interact in the forward method. The forward method describes how the input data passes through the network and comes together as a computation graph. The following code implements a classic multilayer perceptron with two hidden layers:
use ;
use ;
Coding the number of inputs and outputs as variables allows us to reuse the same code for datasets with different numbers of features and classes. The linear function creates a fully connected layer that takes the number of input and output nodes as arguments. Nonlinear activation functions (ReLU) are placed between the hidden layers.
Creating a Model Instance
We can instantiate a new neural network object as follows:
use ;
use ;
Before using this model, we can print it to see its structure:
println!;
This prints something like:
NeuralNetwork {
layer_1: Linear { ... },
layer_2: Linear { ... },
output_layer: Linear { ... }
}
Counting Trainable Parameters
Next, let's check the total number of trainable parameters in this model:
println!;
This prints:
Total number of trainable model parameters: 2213
Each parameter in the VarMap is trainable and will be updated during training.
Inspecting Layer Weights
In our neural network model, the trainable parameters are contained in the Linear layers. A Linear layer multiplies the inputs with a weight matrix and adds a bias vector. This is sometimes referred to as a feedforward or fully connected layer.
We can access the weight parameter matrix of the first layer:
println!;
This prints:
[[-0.2709, 0.1136, -0.2754, ..., 0.2414, -0.0017, 0.2840],
[-0.0263, 0.0686, 0.5760, ..., 0.3354, 0.1075, 0.0547],
[-0.2206, 0.0207, -0.2632, ..., -0.0896, 0.2400, -0.1271],
...
[-0.1658, -0.1832, -0.2016, ..., 0.0093, -0.0543, 0.3168],
[-0.1934, -0.1501, 0.1322, ..., -0.2806, -0.2028, -0.0779],
[ 0.3975, 0.0921, -0.0050, ..., 0.1652, 0.1653, 0.1574]]
Tensor[[30, 50], f32]
Let's check its dimensions:
println!;
The result is:
[30, 50]
The weight matrix is a 30 × 50 matrix. These weights are initialized with small random numbers, which differ each time we instantiate the network. In deep learning, initializing model weights with small random numbers is desired to break symmetry during training. Otherwise, the nodes would perform the same operations and updates during backpropagation, which would not allow the network to learn complex mappings.
Using the Model for Forward Pass
Now let's see how the network is used via the forward pass:
let x = rand?;
let output = model.forward?;
println!;
The result is something like:
[[0.4167, 1.0375, 0.6351]]
Tensor[[1, 3], f32]
We generated a single random training example as a toy input (note that our network expects 50-dimensional feature vectors) and fed it to the model, returning three scores.
The forward pass refers to calculating output tensors from input tensors. This involves passing the input data through all the neural network layers, starting from the input layer, through hidden layers, and finally to the output layer.
Converting Logits to Probabilities
In Candle, it's common practice to code models such that they return the outputs of the last layer (logits) without passing them to a nonlinear activation function. That's because loss functions combine the softmax (or sigmoid for binary classification) operation with the loss computation in a single operation for numerical efficiency.
If we want to compute class-membership probabilities for our predictions, we call the softmax function explicitly:
use softmax;
let output = model.forward?;
let probabilities = softmax?;
println!;
This prints something like:
Tensor[[0.3113, 0.3934, 0.2952]]
The values can now be interpreted as class-membership probabilities that sum up to 1. The values are roughly equal for this random input, which is expected for a randomly initialized model without training.
Setting Up Data Loaders
Before we can train our model, we need to set up data loaders to iterate over our dataset during training. The overall idea is to create a Dataset that holds our data, then create a DataLoader that samples batches from it.
Creating a Toy Dataset
Let's start by creating a simple toy dataset of five training examples with two features each. We also create labels for these examples: three belong to class 0, and two belong to class 1. In addition, we make a test set consisting of two entries:
use ;
Note that class labels should start with 0, and the largest class label value should not exceed the number of output nodes minus 1. So if we have class labels 0, 1, 2, 3, and 4, the neural network output layer should consist of five nodes.
Defining a Dataset Struct
Next, we create a custom Dataset struct to hold our data:
Let's create training and testing datasets:
// We clone the tensors because Dataset::new takes ownership.
// This keeps the originals available if needed later.
// For large datasets, consider using references to avoid cloning overhead.
let train_ds = new;
let test_ds = new;
The main components of our Dataset are:
newmethod that sets up the features and labelsget_itemmethod that returns exactly one data record and its label via an indexlenmethod that returns the total length of the dataset
We can verify the length:
println!; // Prints: 5
Creating a DataLoader
Now we create a DataLoader that samples batches from our dataset. In Rust, we implement this using the Iterator trait, which allows us to create batches on-demand rather than pre-computing all batches upfront.
use SliceRandom;
Let's create data loaders for training and testing:
let train_loader = new?;
let test_loader = new?;
The parameters are:
batch_size: How many examples per batchshuffle: Whether to shuffle the data (useful for training)drop_last: Whether to drop the last incomplete batch
Iterating Over Batches
We can iterate over the data loader:
for in train_loader.iter.enumerate
The result is:
Batch 1: [[-0.9000, 2.9000],
[-0.5000, 2.6000]]
Tensor[[2, 2], f32] [0, 0]
Tensor[[2], u32]
Batch 2: [[ 2.3000, -1.1000],
[-1.2000, 3.1000]]
Tensor[[2, 2], f32] [1, 0]
Tensor[[2], u32]
The data loader iterates over the training dataset, visiting each training example exactly once. This is known as a training epoch. Since we set shuffle=true, the order of examples will be different each time we create a new data loader.
Why Drop Last Batch?
We specified a batch size of 2, but if we had set drop_last=false, the last batch might contain only one example (since 5 is not evenly divisible by 2). Having a substantially smaller batch as the last batch in a training epoch can disturb convergence during training. Setting drop_last=true prevents this by omitting the incomplete last batch.
Building From Scratch
Unlike PyTorch, which has built-in Dataset and DataLoader classes, we built these from scratch in Candle. This gives us more control and helps understand what's happening under the hood. The core concepts remain the same:
- A dataset holds data and provides individual items
- A data loader batches items together and handles shuffling
- We iterate through batches during training
A Typical Training Loop
Let's now train a neural network on our toy dataset. The following code shows the training loop:
use ;
use cross_entropy;
let varmap = new;
let vb = from_varmap;
// The dataset has two features and two classes
let model = new?;
// Create optimizer with learning rate 0.5
let mut optimizer = SGDnew?;
let num_epochs = 3;
for epoch in 0..num_epochs
Running this code yields output like:
Epoch: 001/003 | Batch 001/002 | Train Loss: 3.64
Epoch: 001/003 | Batch 002/002 | Train Loss: 0.00
Epoch: 002/003 | Batch 001/002 | Train Loss: 3.33
Epoch: 002/003 | Batch 002/002 | Train Loss: 0.00
Epoch: 003/003 | Batch 001/002 | Train Loss: 0.00
Epoch: 003/003 | Batch 002/002 | Train Loss: 0.00
As we can see, the loss reaches near 0 after three epochs, a sign that the model converged on the training set.
Understanding the Training Process
Here, we initialize a model with two inputs and two outputs because our toy dataset has two input features and two class labels to predict. We use a stochastic gradient descent (SGD) optimizer with a learning rate of 0.5.
The learning rate is a hyperparameter—a tunable setting we must experiment with based on observing the loss. Ideally, we want to choose a learning rate such that the loss converges after a certain number of epochs. The number of epochs is another hyperparameter to choose.
As discussed earlier, we pass the logits directly into the cross_entropy loss function, which applies the softmax function internally for numerical efficiency. In Candle, optimizer.backward_step(&loss) does both the gradient computation and the parameter update in one call, which is convenient.
Making Predictions
After training the model, we can use it to make predictions:
let outputs = model.forward?;
println!;
The results might look like:
[[ 4.7010e1, -3.7848e1],
[ 4.2802e1, -3.4469e1],
[ 3.7059e1, -2.9854e1],
[ -6.4291e0, -3.9145e-1],
[ -8.2538e0, 3.6420e-2]]
Tensor[[5, 2], f32]
Converting to Probabilities
To obtain the class membership probabilities, we use the softmax function:
use softmax;
let probas = softmax?;
println!;
This outputs something like:
[[ 1.0000e0, 1.4011e-37],
[ 1.0000e0, 2.7653e-34],
[ 1.0000e0, 8.7143e-30],
[ 2.3815e-3, 9.9762e-1],
[ 2.5089e-4, 9.9975e-1]]
Tensor[[5, 2], f32]
Looking at the first row, the first value means the training example has a 99.91% probability of belonging to class 0 and a 0.09% probability of belonging to class 1.
Getting Class Labels
We can convert these values into class label predictions using the argmax function, which returns the index position of the highest value in each row:
let predictions = probas.argmax?;
println!;
This prints:
[0, 0, 0, 1, 1]
Tensor[[5], u32]
Note that it's unnecessary to compute softmax probabilities to obtain the class labels. We can apply argmax to the logits directly:
let predictions = outputs.argmax?;
println!;
The output is the same:
[0, 0, 0, 1, 1]
Tensor[[5], u32]
Computing Accuracy
We can check if our predictions match the true labels:
println!;
This outputs:
[5]
Tensor[[], u8]
Since the dataset consists of five training examples, we have five out of five predictions correct, which is 5/5 × 100% = 100% prediction accuracy.
To generalize the computation of prediction accuracy, let's implement a function:
The code iterates over a data loader to compute the number and fraction of correct predictions. This method scales to datasets of arbitrary size since, in each iteration, the dataset chunk that the model receives is the same size as the batch size seen during training.
We can apply the function to the training set:
let accuracy = compute_accuracy?;
println!;
The result is:
1
Similarly, we can apply it to the test set:
let accuracy = compute_accuracy?;
println!;
This prints:
1
Both show 100% accuracy, indicating our model learned the toy dataset perfectly!
Saving and Loading Models
Now that we've trained our model, let's see how to save it so we can reuse it later.
Saving a Model
Candle uses the SafeTensors format for saving models, which is a safe and efficient way to store tensor data:
// Save model
varmap.save?;
The varmap is a collection that holds all the model's trainable parameters (weights and biases). "model.safetensors" is the filename for the model file saved to disk. The .safetensors extension is the standard convention for this format.
Loading a Model
Once we've saved the model, we can restore it from disk:
The process works in three steps:
- Create a new VarMap: We create an empty
VarMapto hold the loaded parameters - Reconstruct the model architecture: We create a new
NeuralNetworkinstance with the same architecture (2 inputs, 2 outputs) as the saved model - Load the parameters: We call
varmap_loaded.load()to read the file and populate the VarMap with the saved weights and biases
The model architecture (here NeuralNetwork::new(2, 2)) needs to match the original saved model exactly. If the architecture doesn't match, the loading will fail because the parameter shapes won't align.
Also note that variable names must match exactly—the layer prefixes like "l1", "l2", and "out" used during model creation must be identical when loading.
Verifying the Loaded Model
We can verify that the loaded model works correctly by computing accuracy:
let accuracy = compute_accuracy?;
println!;
This should give the same accuracy as before saving, confirming that the model's learned parameters were successfully restored.
Why SafeTensors?
SafeTensors is a modern format designed specifically for safely storing and loading tensor data. It's:
- Fast: Efficient serialization and deserialization
- Safe: Prevents arbitrary code execution during loading
- Portable: Works across different frameworks and languages
This makes it ideal for sharing models and deploying them in production environments.
Conclusion
We've covered the basics of working with Candle—tensor operations, building neural networks, automatic differentiation, and training models. By porting PyTorch examples to Candle, we've seen that the core concepts of deep learning remain the same across frameworks.
While we used a simple toy dataset here, these concepts scale to real-world applications.
The full code is available on GitHub! Happy coding! 😊